
_900.png "Liberte Todo o Potencial da GPU: Sobreponha Comunicação e Computação com Triton-Distributed")
Na computação distribuída, cargas de trabalho de IA exigem alto paralelismo e movimentação eficiente de dados. Um dos principais desafios é sobrepor eficientemente a computação com a comunicação para maximizar o desempenho. As GPUs são excelentes em processar cálculos, mas seu potencial muitas vezes não é totalmente aproveitado devido ao tempo relativamente longo de comunicação entre GPUs. Isso faz com que suas unidades de computação fiquem ociosas por longos períodos enquanto aguardam outras transferências de dados. Neste texto, mostraremos como você pode usar o framework Triton-Distributed para gerar kernels que sobrepõem modelos de comunicação, resultando em desempenho comparável a bibliotecas altamente otimizadas.
O que é o Triton-Distributed Compiler?
O Triton-Distributed é uma extensão inovadora do framework OpenAI Triton que permite a execução simultânea de computação e transferência de dados entre GPUs. Seu objetivo é transformar a forma como os desenvolvedores lidam com o equilíbrio entre desempenho e a sobrecarga de latência induzida pelo compilador. O Triton-Distributed capacita os desenvolvedores a escrever kernels que otimizam automaticamente tanto os cálculos locais quanto os padrões de comunicação entre dispositivos. Por exemplo, um único kernel do Triton-Distributed pode ajustar dinamicamente os padrões de acesso à memória para ocultar latência durante operações como all-reduce.
O Triton-Distributed Compiler herda os pontos fortes do OpenAI Triton, um compilador conhecido por simplificar a programação de GPUs. Em CUDA/HIP, a criação de kernels otimizados exige profundo conhecimento em microarquitetura de hardware e programação de baixo nível, o que demanda ajustes manuais complexos (propensos a erros e demorados) ou o uso de bibliotecas rígidas que limitam a flexibilidade. O Triton muda essa equação, oferecendo um nível mais alto de abstração enquanto mantém flexibilidade, eficiência e produtividade.
Ao encapsular otimizações complexas, como gerenciamento de memória compartilhada, uso de núcleos de tensor/matriz e paralelismo em nível de warp, em passes de compilação reutilizáveis, o Triton-Distributed permite que os desenvolvedores se concentrem na inovação algorítmica em vez de detalhes arquitetônicos de baixo nível. Imagine escrever um kernel de multiplicação de matrizes uma vez e alcançar desempenho comparável a bibliotecas altamente ajustadas para várias configurações de entrada em múltiplos nós de GPU.
O Triton-Distributed visa oferecer:
Kernels eficientes comparáveis a bibliotecas altamente otimizadas, como Distributed-GEMM, cuBLASMp e FLUX.
Abstrações de alto nível e um design focado em produtividade, tornando a portabilidade de desempenho acessível a um público mais amplo.
A abstração da complexidade da programação distribuída em GPUs em uma compilação acessível e extensível.
Vamos explorar como começar com o Triton-Distributed.
Começando com o Triton-Distributed
A seguir estão os passos para instalar e usar o Triton-Distributed em GPUs AMD.
Passo 1. Instale o Triton-Distributed a partir do código-fonte:
Consulte o Guia de Compilação para melhores práticas na compilação e configuração do TritonDistributed para GPUs AMD.
Passo 2. Como usar o Triton-Distributed:
O Triton-Distributed fornece um conjunto de primitivas de fácil uso para desenvolver kernels que sobrepõem computação e comunicação. Todas as primitivas são expostas por [triton.distributed.language], que são recursos adicionais que complementam os principais recursos do Triton, mantendo sua composição sem modificar o núcleo.
As primitivas são divididas em conjuntos de baixo e alto nível. Enquanto as primitivas de alto nível (descritas no artigo MLSys 2025) serão lançadas no futuro, a versão atual inclui as seguintes primitivas
de baixo nível:
Primitivas de Baixo Nível – Consulta de Contexto
- rank(axis=-1, _builder=None)
- num_ranks(axis=-1, _builder=None)
- symm_at(ptr, rank, _builder=None)
Primitivas de Baixo Nível – Controle de Sinal
- wait(barrierPtrs, numBarriers, scope: str, semantic: str,
_builder=None) - consume_token(value, token, _builder=None)
- notify(ptr, rank, signal=1, sig_op="set", comm_scope="inter_node",
_builder=None)
Os usuários podem combinar a parte de comunicação com a parte de computação para projetar kernels sobrepostos.
Teste e Reproduza o Desempenho com Triton-Distributed em AMD CDNA3
Abaixo está o script para testar e reproduzir o desempenho do ReduceScatter GEMM em um único nó:
#!/bin/bash
set -e
SHAPES=(
"8192 4096 12288"
"8192 4096 14336"
"8192 3584 14336"
"8192 4608 36864"
"8192 8192 28672"
"8192 8192 30720"
)
for shape in "${SHAPES[@]}"; do
read -r m n k <<< "$shape"
echo "Testing GEMM_RS shape: m=$m, n=$n, k=$k"
bash ./third_party/distributed/launch_amd.sh
./third_party/distributed/distributed/test/amd/test_gemm_rs_intra
_node.py ${m} ${n} ${k} --warmup 5 --iters 20
done
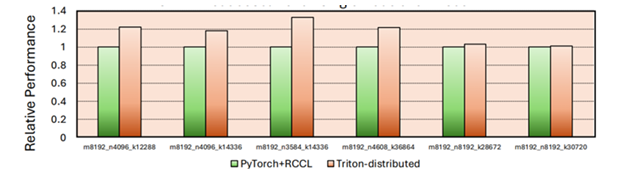
A Figura 1 abaixo mostra o aumento de desempenho ao usar o Triton-Distributed em comparação com RocmBlas+RCCL. Nos casos ajustados, observamos uma melhoria de 30% com essa abordagem.
AllGather GEMM em Nó Único
Abaixo está o script para testar e reproduzir o desempenho do AllGather GEMM em um único nó:
set -e
SHAPES=(
"8192 4096 12288"
"8192 4096 14336"
"8192 3584 14336"
"8192 4608 36864"
"8192 8192 28672"
"8192 8192 30720"
)
for shape in "${SHAPES[@]}"; do
read -r m n k <<< "$shape"
echo "Testing AG_GEMM shape: m=$m, n=$n, k=$k"
bash ./third_party/distributed/launch_amd.sh
./third_party/distributed/distributed/test/amd/test_ag_gemm_intra_node.py
${m} ${n} ${k} --warmup 5 --iters 20
done
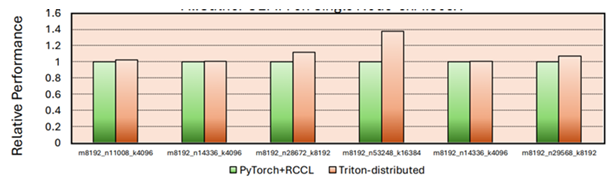
A Figura 2 abaixo mostra o aumento de desempenho ao usar o Triton-Distributed em comparação com
RocmBlas+RCCL. Nos casos ajustados, observamos uma melhoria de 30-40% com essa abordagem.
Resumo
O Triton-Distributed é um compilador baseado no framework Triton da OpenAI e representa um avanço na computação distribuída em GPUs. Ele aborda um dos maiores desafios em cargas de trabalho de IA: equilibrar eficientemente a computação com a comunicação entre GPUs. Ao permitir a sobreposição de computação e comunicação, o Triton-Distributed possibilita que os kernels continuem processando enquanto os dados são transferidos, maximizando assim a utilização da GPU, reduzindo ciclos ociosos e melhorando o desempenho geral do sistema.
O Triton-Distributed herda as abstrações de alto nível do Triton, eliminando a necessidade de conhecimento profundo de hardware ou o uso de bibliotecas rígidas. Ele permite a criação de kernels distribuídos portáteis e de alto desempenho—como o Distributed-GEMM—que rivalizam com implementações em CUDA otimizadas manualmente. Ao encapsular otimizações complexas, como gerenciamento de memória compartilhada e paralelismo em nível de warp, em passes de compilação, ele capacita os desenvolvedores a focar no design algorítmico em vez de detalhes de baixo nível.
Além disso, o Triton-Distributed traz essas capacidades para GPUs AMD, ampliando o acesso e a portabilidade de desempenho entre diferentes plataformas de hardware. Ele oferece uma solução de ponta que permite aos desenvolvedores:
- Libertar todo o potencial do hardware AMD GPU
- Expandir os limites do desempenho distribuído
- Acelerar a inovação em sistemas de IA













